Mistral releases Leanstral 1.5: 119B/6B-active Apache-2.0 prover saturates miniF2F and finds 5 unknown Rust bugs at $4 per problem
On 2026-07-02, Mistral AI released Leanstral 1.5 — a 119B-total / 6B-active mixture-of-experts proof engineering model for Lean 4, under Apache-2.0 and hosted on Hugging Face (Mistral blog post). Headline numbers: it saturates miniF2F at 100% on both validation and test sets, solves 587 of 672 PutnamBench problems, and hits a new state of the art on FATE-H (87%) and FATE-X (34%) — at about $4 per problem, against the $300+ Mistral estimates for closed-source competitors.
What shipped
Leanstral 1.5 is the second-generation release in Mistral’s Leanstral line (the first is Leanstral-2603). From the Hugging Face card: MoE 128 experts / 4 active per token, 119B total / 6.5B activated, 256k context, multimodal input (text + image → text), Apache-2.0, recommended temperature 1.0 with reasoning effort high for complex proofs. It ships in the Mistral Small 4 family and is available as a free API endpoint (leanstral-1-5) and through Mistral Vibe.
How it was trained
Three stages — mid-training, supervised fine-tuning, reinforcement learning with CISPO — across two RL environments (blog). The multiturn environment gives the model a theorem, accepts a proof attempt, returns Lean compiler feedback, and refines until the proof compiles or the budget runs out. The code agent environment puts the model in a raw filesystem where it edits files, runs bash, and uses the Lean language server; it persists through context compactions to finish partial proofs, build auxiliary lemmas, and navigate real repos. Every run is verified by Mistral’s fork of SafeVerify.
Benchmarks
| Benchmark | Leanstral 1.5 | Closest closed competitor | Mistral’s stated cost |
|---|---|---|---|
| miniF2F (val/test) | 100% / 100% | — (saturated) | — |
| PutnamBench (672 problems) | 587 | Seed-Prover 1.5 high: 580 | ~$4 / problem vs ~$300+ |
| FATE-H | 87 (SOTA) | Seed-Prover 1.5 high: 80 | — |
| FATE-X | 34 (SOTA) | Seed-Prover 1.5 high: 33 | — |
| FLTEval pass@1 | 28.9 | Leanstral 1.0: 21.9 | “one-seventh the cost” of Opus 4.6 |
| FLTEval pass@8 | 43.2 | Opus 4.6: 39.6 | — |
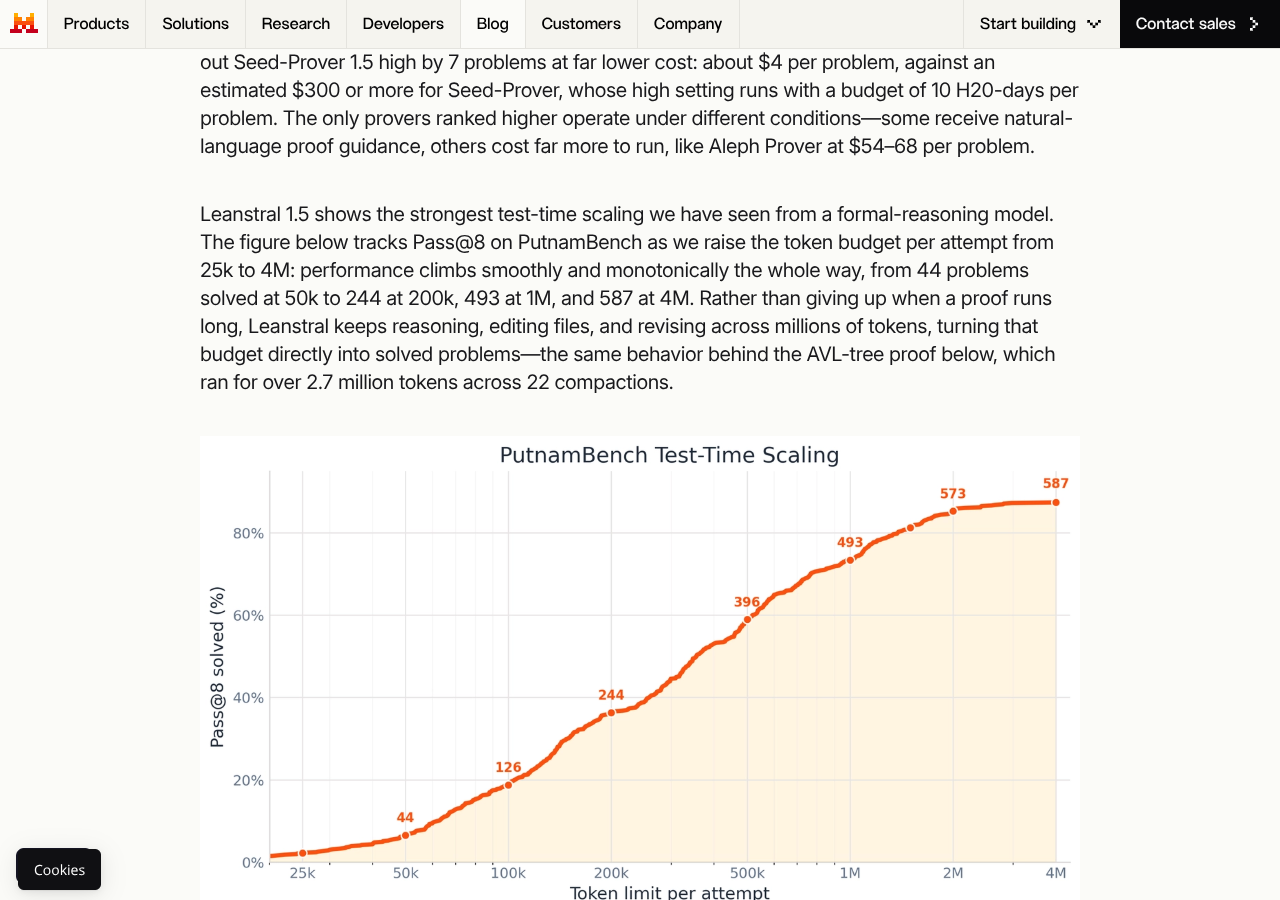
Mistral notes the only provers ranked higher on PutnamBench operate under different conditions — some receive natural-language proof guidance, others cost more (e.g. Aleph Prover at $54–$68 per problem, Seed-Prover 1.5 high at 10 H20-days per problem) (blog).
Real-world code verification
Two case studies. First, an AVL-tree insertion/deletion proof on a real implementation. The model ran over 2.7 million tokens across 22 compactions, unfolded each layer of the TimeM monad, established an almost-tight bound of 48 steps per height unit, and connected height to tree size via a logarithmic relationship — completing verified proofs that insertion and deletion are O(log n).
Second, automatic bug discovery. Mistral’s pipeline uses Aeneas to translate Rust to Lean, then Leanstral infers user intent, generates correctness properties, and attempts to prove them. Across 57 repositories the pipeline flagged 47 violated properties, 11 genuine bugs, 5 previously unreported on GitHub (blog).
One example: the sign function for zigzag decoding in datrs/varinteger. On input Std.U64.MAX, (value + 1) overflowed — debug-mode crashes, release-mode silent corruption. Caught without fuzzing.
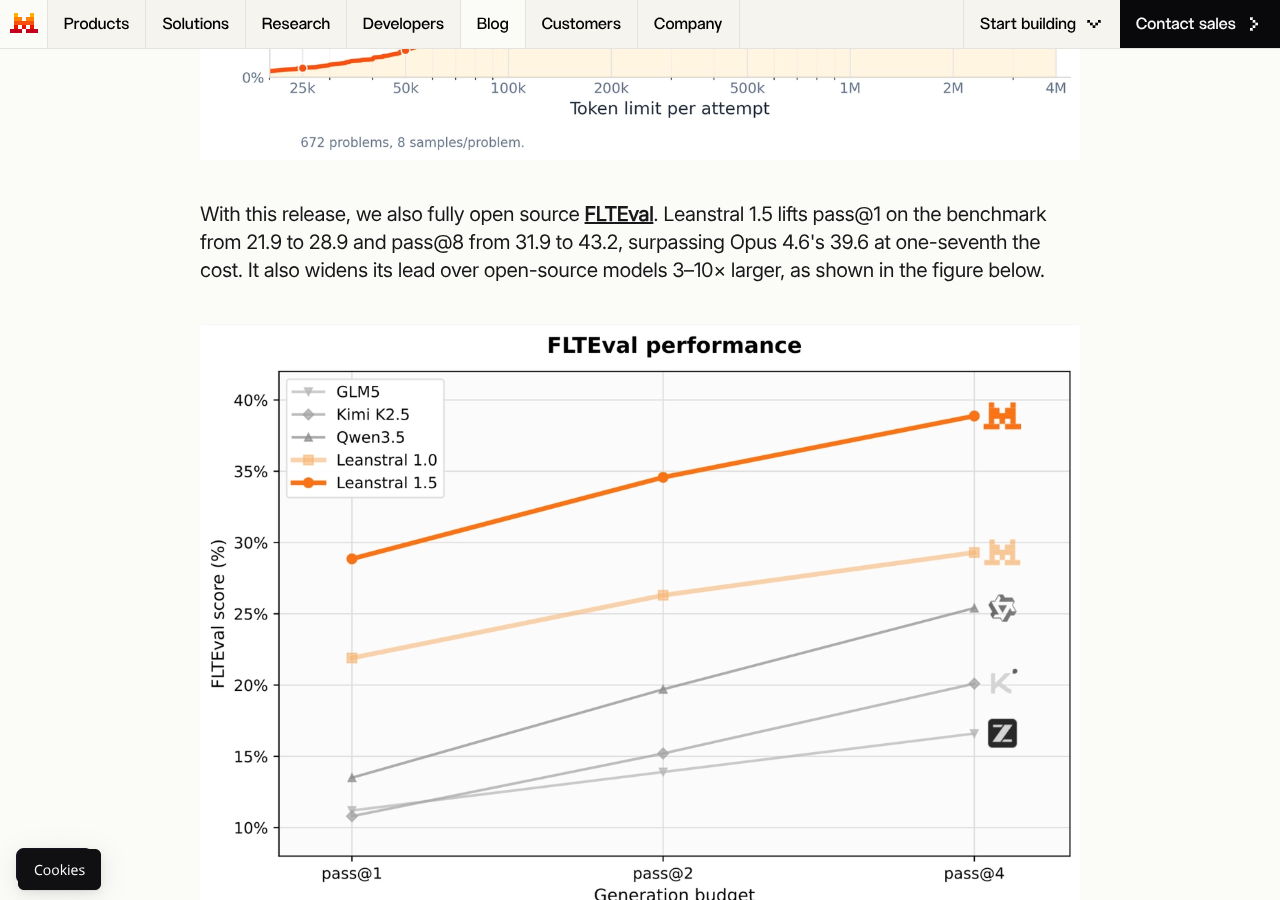
Alongside the model, Mistral also fully open-sourced the FLTEval harness at github.com/mistralai/FLTEval (Apache-2.0) — a Docker-only SWE-bench-shaped harness that applies submitted diffs inside per-task images, runs Lean and SafeVerify, and writes per-instance and aggregate reports.
Practical implications
- Lean 4 contributors. Drop the weights into
vllm(≥ 0.24.0) and run them locally, or hitleanstral-1-5on Mistral’s free API tier. Recommended path:vibe --agent leanwith the Lean LSP MCP. - Rust teams piloting formal verification. The Rust-to-Lean pipeline (Aeneas + Leanstral + property generation) is a working reference for “small spec, no spec” adoption. The 5-bug hit rate across 57 repos justifies a serious pilot.
- Proof-engineering research. FLTEval being open-source is the more durable contribution. It runs on the real Fermat’s Last Theorem pull-request history, grounding the benchmark in actual mathematical software, not synthetic problems.
Risks and caveats
- Benchmark saturation ≠ capability. miniF2F is curated; the 5-bugs-across-57-repos result is the strongest signal of generalization to new Lean 4 codebases.
- “$4 per problem” is Mistral’s number. Not directly reproducible on a third-party vLLM deployment; the $300+ comparator is also Mistral’s estimate. Both are directional.
- The 2.7M-token AVL proof is a one-shot demonstration. Long-horizon proof quality across many runs is not reported.
- Closed-source comparators operate under different conditions. Higher-ranked PutnamBench provers receive natural-language guidance or run at higher per-problem cost. The SOTA framing is correct within Mistral’s chosen comparison set.
- Multimodal input is unproven for proof work. Public evaluations are text-only.
What to watch
- FLTEval adoption. A new open benchmark lives or dies on outside reporting. The 162-instance sample is the seed; the full public dataset is meant to live on Hugging Face.
- Mistral Vibe as the distribution channel. If
vibe --agent leanbecomes the default Lean 4 workflow, the practical impact will exceed the benchmark numbers. - Leanstral 2.x cadence. A 2.x bump is the natural place for test-time scaling to push past 4M tokens.
- Independent reproduction of the bug-finding rate. Whether outside teams reproduce the ~10% genuine-bug rate on their own codebases is the strongest test of the practical claim.