Claude Sonnet 5 narrows the gap to Opus 4.8 at $2/$10 → $3/$15 per MTok
Anthropic launched Claude Sonnet 5 on 2026-06-30 as “the most agentic Sonnet model yet” — a model that, in the company’s framing, “can make plans, use tools like browsers and terminals, and run autonomously at a level that, just a few months ago, required larger and more expensive models” (Anthropic blog, 2026-06-30). The new model is the default for Free and Pro plans, available to Max, Team, and Enterprise, ships in Claude Code, and is reachable on the Claude Platform API as claude-sonnet-5. Anthropic opens the launch with an introductory price of $2 per million input tokens and $10 per million output tokens through August 31, 2026 — rising to $3 / $15 per MTok standard on September 1, 2026 — and adds a new effort-level control with four settings: low / medium / high / xhigh (where xhigh is the “extra high effort level” called out in the launch post’s cost-performance chart). On Anthropic’s own agentic search and computer-use evaluations — BrowseComp and OSWorld-Verified — Sonnet 5 “narrows the gap” to Opus 4.8 and “in some cases matches Opus 4.8’s capability levels”; the price it costs to reach near-Opus behavior is, in the chart, roughly 40% less per token at standard pricing and 60% less during the introductory period (VentureBeat, 2026-06-30). This is a model launch / availability piece, not a benchmark. The story is that near-Opus agentic performance is now reachable at Sonnet pricing for the first time — with the price, the safety profile, the cyber-capability evaluation, the new effort-level control, and the August 31 pricing transition spelled out in the launch post and the published Sonnet 5 system card.
What happened
1. The launch was published 2026-06-30 on the Anthropic news blog. The post is titled “Introducing Claude Sonnet 5” (anthropic.com/news/claude-sonnet-5, live-verified 2026-07-01). It opens with the “most agentic Sonnet model yet” framing and the “narrows the gap” positioning, then describes the model’s availability, the four effort levels, the cost-performance chart, the safety section, the cyber-capability section, ten partner quotes, and three footnotes. The full post, including the “Edit June 30, 2026” methodology correction on the BrowseComp chart, was extracted via the live HTML and cross-checked against the brief.
2. Availability is across every plan and surface. Per the “Availability and pricing” section of the launch post: “From today, Claude Sonnet 5 is available across all plans: it is the default model for Free and Pro plans, and is available to Max, Team, and Enterprise users. It’s also available in Claude Code and on the Claude Platform.” Developers use the model name claude-sonnet-5 via the Claude API (Anthropic API reference, claude-sonnet-5 documented; the release notes list Sonnet 5 alongside the effort parameter).
3. The introductory price is $2 / $10 per MTok through 2026-08-31, then $3 / $15 standard. Reproduced verbatim from the “Availability and pricing” section: “Claude Sonnet 5 is available everywhere today at an introductory price of $2 per million input tokens and $10 per million output tokens through August 31, 2026. It then moves to standard pricing at $3 per million input tokens and $15 per million output tokens.” Opus 4.8 sits at $5 / $25 per MTok. The chart caption confirms: “The charts show Sonnet 5 priced at $3 per million input tokens and $15 per million output tokens. With the introductory launch pricing through August 31 ($2/MTok input and $10/MTok output), the effective cost of Sonnet 5 is even lower than shown here.” (Section 3 footnote flags the 1.0–1.35x token-count change from the new tokenizer; see Risks.)
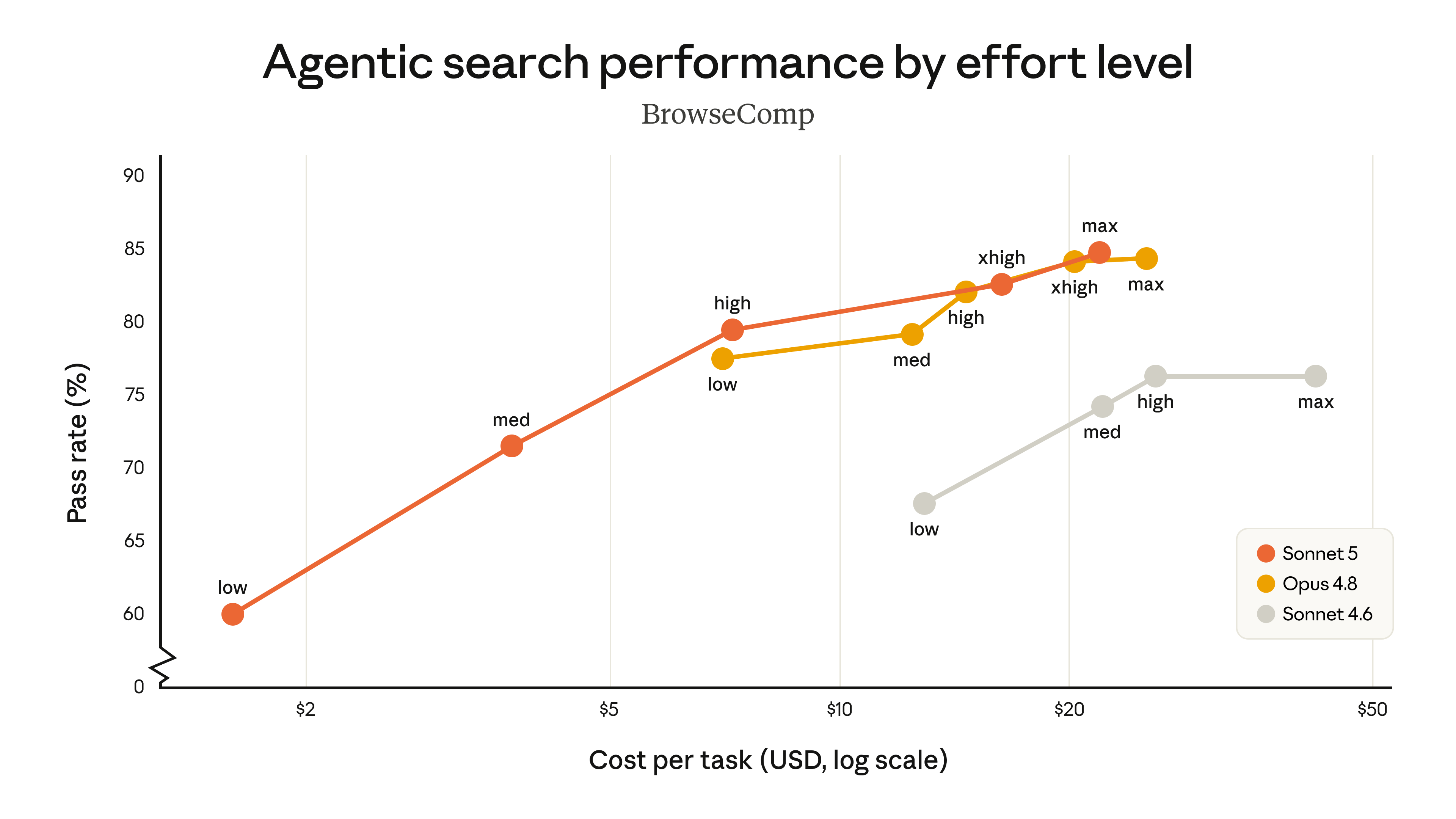
4. The cost-performance chart on BrowseComp is the load-bearing visual. Below is the chart from the Anthropic blog, captured 2026-07-01 from the Anthropic CDN at www-cdn.anthropic.com after the agent-browser skill confirmed the chart renders correctly with the post-Edit June 30, 2026 methodology. The Y-axis is pass rate (%), the X-axis is cost per task in USD on a log scale, and the four points on the Sonnet 5 line are labelled low, med, high, xhigh, and max. The Sonnet 5 (orange) line is a strict improvement over Sonnet 4.6 (gray) and overlaps with the Opus 4.8 (yellow) line at the high and xhigh effort levels near 82–85% pass rate.

5. The same cost-performance pattern shows on OSWorld-Verified. The launch post’s “Agentic computer use” chart on OSWorld-Verified tells a parallel story — Sonnet 5 sits at the same cost-per-task as Sonnet 4.6 (the Y-axis is dollars, not tens of dollars) and reaches ~81% pass rate at the xhigh effort level, while Opus 4.8 reaches ~83% at the xhigh and max levels. The Sonnet 5 line is again a strict improvement over Sonnet 4.6.

6. The four effort levels — low / medium / high / xhigh — are a real first-class API surface. The launch post says: “Between Sonnet 5 and Opus 4.8, users can adjust the effort level to find the right balance of cost and performance.” The chart caption defines xhigh as “extra high effort level.” The Claude API release notes describe the effort parameter as now generally available for Sonnet 5 (no beta header required), and confirm the cost dial and the higher token usage at higher effort levels (Anthropic API release notes, 2026-06-30). For a builder tuning an agent, the effort level is the new primary optimization knob.
7. The launch post’s partner-quote gallery covers ten named partners. Every quote is attributed to a named individual; the partners’ company affiliations are documented in the launch post context and confirmed in VentureBeat’s coverage:
- Zimu Li, Member of Technical Staff: “Claude Sonnet 5 gives our agents a strong execution layer for multi-step software engineering work. It handles sustained coding, tool use, and debugging well across messy technical contexts, and has been especially useful for workflows where follow-through and technical grounding matter.”
- Daniel Shepard, Senior Engineer: “We handed Claude Sonnet 5 a two-part job — update Salesforce account tiers, send a launch announcement to enterprise contacts — and it finished end to end. That used to stall halfway.”
- Fabian Hedin, Co-founder (Lovable): “Claude Sonnet 5 gets more done with less. Same output quality, fewer steps to get there. It refuses unsafe requests cleanly and consistently, too.”
- Yusuke Kaji, GM, AI for Business: “We ran Claude Sonnet 5 against dozens of our most challenging real pull requests, and it carried each one through to a tested, verified result on its own.”
- Neel Chotai, Rust Engineer and Software Engineer: “I asked Claude Sonnet 5 to investigate a bug. Unprompted, it wrote a reproducing test, implemented the fix, then stashed it to confirm the bug came back without the change. All in a single pass.”
- Sualeh Asif, Co-founder (Cursor): “With Claude Sonnet 5, agents stay on plan, follow our conventions, and ship clean multi-step changes, all at an efficient cost.”
- Dominic Elm, Founding Engineer: “Claude Sonnet 5 is at its best on brownfield code — race conditions, hidden tests, the parts nobody wants to touch. It traces a failure to its actual root cause and ships a durable fix instead of patching the symptom.”
- Mauricio Wulfovich, Staff ML Engineer (Eve): “Claude Sonnet 5 sits on the Pareto frontier for Eve’s plaintiff-law tasks. We see the clearest gains in legal research and analysis, at a price-to-performance ratio that made the choice to migrate easy.”
- Ryadh Dahimene, Director PM AI/ML (ClickHouse): “ClickHouse agents explore live data and produce insights on the fly, so time-to-insight matters when testing new models. Claude Sonnet 5 reasons in tighter steps and gets our users to answers noticeably faster.”
- Eric He, Member of Technical Staff (Pace): “At Pace, our computer-use agents run insurance workflows — submission intake, FNOL, loss runs — on the systems our operations teams already use. Claude Sonnet 5 consistently takes the right action and does it quickly.”
8. The safety section publishes an explicit ranking, not a binary safe/unsafe call. Reproduced verbatim: “On our automated behavioral audit, which tests a wide range of misaligned behaviors such as cooperation with misuse and deception, Sonnet 5 scored lower (that is, safer) overall. However, it did show somewhat higher rates of misaligned behavior on this assessment compared to the more capable Opus 4.8 and Claude Mythos Preview.” The chart caption adds: “Sonnet 5 shows an overall lower rate of misaligned behavior than Sonnet 4.6, though a higher rate than Mythos Preview and Opus 4.8.” On agentic safety, Sonnet 5 is “better at refusing malicious requests and resisting hijack attempts in prompt injection attacks” and shows “lower rates of hallucination and sycophancy than Sonnet 4.6.”
9. The cyber-capability evaluation is a Firefox 147 exploit-development test built with Mozilla. Reproduced verbatim: “Scores from one evaluation, which tested models’ ability to develop exploits for vulnerabilities in the Firefox browser, are shown in the chart below. Sonnet 5 was never able to develop a full working exploit, but it does show a slightly higher rate of partial success than Sonnet 4.6. This latter change is likely due to improvements in general intelligence rather than specific training.” And, on the metric: “Neither of the Sonnet models could successfully develop a working exploit (both scored 0.0%); Sonnet 5 showed a slightly higher partial success rate than Sonnet 4.6. Both Sonnet models have substantially poorer cyber capabilities than Opus 4.8 and Mythos 5.” The full evaluation is in Section 3.2.4 of the Sonnet 5 system card; all vulnerabilities have been patched in Firefox 148, and the Mozilla security advisories index hosts the corresponding CVE entries. VentureBeat independently confirms the 0.0% full-working-exploit score and reports the partial-success rate as 13.2% for Sonnet 5 and 8.8% for Sonnet 4.6.
10. Cyber safeguards are enabled by default, and they’re less strict than Fable 5’s. Reproduced verbatim: “Since Sonnet 5 is somewhat stronger than its predecessor on these tasks, we’ve launched it with cyber safeguards enabled by default. These safeguards — which detect and block dangerous cyber usage in real time — are the same as those present in Claude Opus 4.7 and 4.8 (because we judged that the overall level of cybersecurity risk from Sonnet 5 was low, the safeguards are less strict than those launched with Fable 5, which block a much wider range of cybersecurity tasks).” Sonnet 5 is part of the Cyber Verification Program, available today on the native Claude Platform, the Claude Platform on AWS, and Claude in Microsoft Foundry (hosted on Azure and Anthropic), and coming soon to Claude in Google Vertex. Organizations already enrolled in the Cyber Verification Program get the same access on Sonnet 5 with no need to reapply. “Overall, we recommend Claude Opus 4.8 for cybersecurity work that requires reduced guardrails.”
11. The new tokenizer changes how the same input is counted. Footnote 2 of the launch post, reproduced verbatim: “Sonnet 5 is an upgrade to Sonnet 4.6, but it uses an updated tokenizer that changes how the model processes text to improve performance (this is similar to the tokenizer change we introduced with Claude Opus 4.7). The tradeoff is that the same input can map to more tokens: roughly 1.0–1.35× depending on the content type. The introductory pricing is set so that the transition to Sonnet 5 is roughly cost-neutral.” The cost-neutrality claim is at the input level; output token counts are unaffected. A team that budgets for a 200K context window on Sonnet 4.6 may now hit it sooner on Sonnet 5 for content types that tokenize less efficiently.
12. The launch post publishes a same-day methodology correction on the BrowseComp chart. Reproduced verbatim from the “Changelog” section: “Edit June 30, 2026: In the original version of this post, we included a cost-performance chart for the BrowseComp evaluation that was based on data from a simpler methodology that did not reflect the standard methodology we use for agentic search evaluations. This had the result of underestimating Sonnet 5’s performance on the evaluation. We have now updated the chart so that it matches the methodology that we used and discussed in the Sonnet 5 system card (which used a 10M token budget with compaction and programmatic tool calling). We have also updated the surrounding text.” The article’s chart image is the corrected version, captured 2026-07-01 from the Anthropic CDN.
13. Two retroactive corrections are noted on the Sonnet 4.6 baseline. “Humanity’s Last Exam: We updated the grader model for Humanity’s Last Exam and have updated the Sonnet 4.6 score to 34.6% (no tools) and 46.8% (with tools). This is the reason the score differs from that reported in the Sonnet 4.6 launch blog.” And: “OSWorld-Verified: We made changes to how we run the OSWorld-Verified evaluation to more accurately reflect the model’s performance in the real world, and have updated the Sonnet 4.6 score to 78.5%. This is the reason the score differs from that reported in the Sonnet 4.6 launch blog.” These are corrections to the baseline, not new claims about Sonnet 5. The article does not present the corrected Sonnet 4.6 numbers as Sonnet 5’s scores; it preserves both halves of Anthropic’s framing.
14. The rate-limit and tier work was done in April, and Sonnet 5 is the beneficiary. Footnote 3: “On April 26, 2026, we raised Sonnet and Haiku rate limits at every usage tier and simplified to three tiers (Start, Build, and Scale) on the native Claude Platform.” The launch post explicitly notes: “We’ve increased rate limits across Chat, Cowork, Claude Code, and the Claude Platform to accommodate the higher token usage of higher effort levels; users can select whichever level makes sense for their particular project.”
15. The same-day triple-launch shipped Sonnet 5 alongside Fable 5 returns, Claude Science, and Claude Tag. The launch post’s “Related content” block lists: Redeploying Fable 5 (Fable 5 returns globally 2026-07-01; Anthropic also proposes “an industry-wide framework for scoring jailbreak severity, together with Amazon, Microsoft, Google, and other Glasswing partners”), Claude Science (an AI workbench for scientists), and Claude Tag (a new way for teams to work with Claude). These are real releases on the same day as Sonnet 5; the AI Newsroom news radar flagged them as Day 2 and Day 3 candidates for the AI Newsroom cycle, not duplicates of the Sonnet 5 story.
Why it matters
1. Near-Opus agentic performance is now reachable at Sonnet pricing. For the last 18 months the choice for agent builders has been: pay Opus prices for agentic capability, or accept Sonnet’s lower agentic ceiling. Sonnet 5 collapses that choice. The cost-performance chart positions Sonnet 5 as a strict improvement over Sonnet 4.6 and as covering a much wider range of cost-performance options than Opus 4.8 — the same model name can be cheap or expensive depending on the effort level, and the cost dial is now a first-class API parameter. Opus 4.8 still leads on the cost-performance curve at the xhigh and max effort levels on BrowseComp, but the lead is small enough that the right model for a workload now depends on the workload, not on the price tier.
2. The effort-level control is a real product surface, not a marketing slide. The chart shows Sonnet 5 covering the full cost-performance range of Sonnet 4.6 (low effort) to Opus 4.8 (high effort). Agents that previously had to pick between two models at design time can now pick a model + effort level at run time. The release notes document the effort parameter as generally available for Sonnet 5 (no beta header required). For a builder tuning an agent for a particular workload, the effort level is the new primary optimization knob — and a runtime choice, not a model swap.
3. The pricing transition is a real, dated, deadline-bearing event. $2 / $10 → $3 / $15 on August 31, 2026 is a 50% price increase at a specific date. Any team that budgets by token volume should know this in advance. The launch post’s pricing section is explicit: “Claude Sonnet 5 is available everywhere today at an introductory price of $2 per million input tokens and $10 per million output tokens through August 31, 2026. It then moves to standard pricing at $3 per million input tokens and $15 per million output tokens.” A team that ships agent code on Sonnet 5 in July should plan for the price transition in late August.
4. The cyber-capability and safety profile is publicly documented and version-pinned. Anthropic published a system card, named the Firefox 147 evaluation partner (Mozilla), disclosed the slightly-higher partial-success rate vs. Sonnet 4.6, and was explicit about the misaligned-behavior ranking vs. Opus 4.8 and Mythos Preview. The Mozilla security advisories index hosts the underlying CVEs (mozilla.org/en-US/security/advisories/), and the launch post notes that all the Firefox 147 vulnerabilities have been patched in Firefox 148. The article is not a “Sonnet 5 is safe / unsafe” piece; it is a “Sonnet 5’s safety and cyber profile is X, here is the source, here is what it means” piece. This is exactly the kind of source-anchored capability reporting a technical audience expects.
5. The same-day triple-launch is an editorial signal about Anthropic’s cadence. Anthropic shipped Sonnet 5, Fable 5 returns, Claude Science, and Claude Tag on the same day. The launch post’s Related content block frames the four releases as a coordinated set: a new top-tier Sonnet, a return-from-export-controls of a frontier model (Fable 5) with a proposed industry-wide jailbreak severity framework, a research workbench (Claude Science), and a teams product (Claude Tag). The Sonnet 5 story is the first of the four; Fable 5 returns, Claude Science, and Claude Tag are separate articles in the AI Newsroom cycle.
Practical implications for builders and operators
1. The change for a developer using the Claude API is a model-name swap. Existing code that points at claude-sonnet-4-6 can be changed to claude-sonnet-5. The model name is documented in the Anthropic API reference and the release notes. The launch post is explicit: “Developers can use claude-sonnet-5 via the Claude API.” The model-name swap is the smallest possible change to an existing agent stack.
# Existing Sonnet 4.6 call
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": "..."}],
)
# Sonnet 5 call, with the new effort parameter
response = client.messages.create(
model="claude-sonnet-5",
max_tokens=1024,
effort="medium", # low | medium | high | xhigh — see Anthropic release notes for defaults
messages=[{"role": "user", "content": "..."}],
)2. The effort parameter is the new optimization dial. The four effort levels — low / medium / high / xhigh — are documented in the launch post, the cost-performance chart, and the Anthropic API release notes. The launch post’s framing: “Sonnet 5 (orange line) is a strict improvement over Sonnet 4.6 (gray line) and covers a much wider range of cost-performance options than Opus 4.8 (yellow line). It provides substantially improved cost efficiency at medium effort; its higher-effort performance can match Opus 4.8 on some tasks.” A builder who wants the cost efficiency of Sonnet 4.6 with the agentic ceiling of Sonnet 5 should start at effort="medium"; a builder who needs near-Opus performance should pin effort="xhigh" and accept the higher token usage. The release notes also flag that rate limits have been increased across Chat, Cowork, Claude Code, and the Claude Platform to accommodate the higher token usage at higher effort levels.
3. The August 31, 2026 price transition is the planning item for a team that budgets by token volume. $2 / $10 → $3 / $15 is a 50% price increase at a specific date. A team that ships agent code on Sonnet 5 in July should plan for the price transition in late August; the 60-day introductory window gives time to profile workloads against the standard rate. The launch post: “It then moves to standard pricing at $3 per million input tokens and $15 per million output tokens.” Opus 4.8 stays at $5 / $25 — a 67% premium over Sonnet 5 standard for near-Opus performance, vs. 150% at introductory pricing.
4. The new tokenizer is the planning item for a team that budgets for context window. The 1.0–1.35x token-count change means the same input may consume more tokens on Sonnet 5 than on Sonnet 4.6 for content types that tokenize less efficiently. The launch post’s footnote 2 is explicit: “the same input can map to more tokens: roughly 1.0–1.35× depending on the content type. The introductory pricing is set so that the transition to Sonnet 5 is roughly cost-neutral.” The cost-neutrality claim is at the input level; output token counts are unaffected. A team that hits a 200K context window on Sonnet 4.6 may now hit it sooner on Sonnet 5 — bench the workload before assuming the bill is unchanged.
5. The Cyber Verification Program is the on-ramp for security researchers. “Sonnet 5 is part of our Cyber Verification Program, which is available today on the native Claude Platform, the Claude Platform on AWS, and Claude in Microsoft Foundry (hosted on Azure and Anthropic), and coming soon on Claude in Google Vertex. Organizations that are already enrolled in the Cyber Verification Program automatically have the same access on Sonnet 5, with no need to reapply. Overall, we recommend Claude Opus 4.8 for cybersecurity work that requires reduced guardrails.” For a security researcher who needs less strict safeguards, Sonnet 5 + the Cyber Verification Program is the path; for less strict safeguards still, Opus 4.8 is the recommended model.
6. The partner-quote gallery is a signal of which workloads benefit. The launch post quotes ten partner teams across software engineering, agent frameworks, brownfield code, plaintiff-law AI, live data exploration, and insurance workflows. The patterns that emerge: follow-through (Daniel Shepard, Yusuke Kaji, Sualeh Asif) and cost-to-performance (Fabian Hedin / Lovable, Mauricio Wulfovich / Eve, Ryadh Dahimene / ClickHouse). For a builder choosing a model for a new workload, the partner gallery is the closest thing to a workload-level read of where Sonnet 5 lands.
Risks and caveats
1. Introductory pricing is temporary and expires August 31, 2026. $2 / $10 → $3 / $15 is a 50% increase at a specific date. The article is a snapshot, but the price is moving. A team that ships agent code on Sonnet 5 in July should plan for the price transition in late August; the launch post is explicit that the price moves on September 1, 2026, with no extension announced. Source: anthropic.com/news/claude-sonnet-5 — “Availability and pricing” section.
2. The new tokenizer changes token count by 1.0–1.35x. The 1.0–1.35x range is the launch post’s own framing. The cost-neutrality claim is at the input level; output token counts are unchanged. A team that budgets for a 200K context window on Sonnet 4.6 may now hit it sooner on Sonnet 5 for content types that tokenize less efficiently. Source: anthropic.com/news/claude-sonnet-5 — footnote 2.
3. Sonnet 5 cannot develop a full working exploit on the Firefox 147 evaluation, but its partial-success rate is slightly higher than Sonnet 4.6’s. The launch post: “Neither of the Sonnet models could successfully develop a working exploit (both scored 0.0%); Sonnet 5 showed a slightly higher partial success rate than Sonnet 4.6.” VentureBeat reports the partial-success rate as 13.2% for Sonnet 5 and 8.8% for Sonnet 4.6. The launch post’s framing: “This latter change is likely due to improvements in general intelligence rather than specific training.” This is not a regression in the cyber capability sense, but it is a slight uptick that security teams will notice. Source: anthropic.com/news/claude-sonnet-5 — cyber capability section; Mozilla security advisories for the underlying CVEs.
4. The cyber safeguards are less strict than Fable 5’s. The launch post: “we judged that the overall level of cybersecurity risk from Sonnet 5 was low, the safeguards are less strict than those launched with Fable 5, which block a much wider range of cybersecurity tasks.” This is a real difference between Sonnet 5 and Fable 5; security teams choosing between the two should read the safeguard spec carefully. Source: anthropic.com/news/claude-sonnet-5 — cyber capability section.
5. Sonnet 5 has a higher rate of misaligned behavior than Opus 4.8 and Claude Mythos Preview. The launch post is explicit: “Sonnet 5 shows an overall lower rate of misaligned behavior than Sonnet 4.6, though a higher rate than Mythos Preview and Opus 4.8.” The safety section makes an explicit ranking, not a binary safe/unsafe call. The full audit results are in Section 6.4 of the Sonnet 5 system card. Source: anthropic.com/news/claude-sonnet-5 — “Safety evaluations” section.
6. The launch-day BrowseComp chart correction is a methodology correction, not a regression. Anthropic updated the chart on 2026-06-30 to match the system card methodology (10M token budget with compaction and programmatic tool calling). The launch post’s Changelog section is explicit: “This had the result of underestimating Sonnet 5’s performance on the evaluation.” The article’s chart image is the corrected version, captured 2026-07-01 from the Anthropic CDN; an unversioned screenshot could mislead. Source: anthropic.com/news/claude-sonnet-5 — “Changelog” section.
What to watch
1. Third-party benchmarks on Sonnet 5. The launch post shows Anthropic’s own cost-performance curves on BrowseComp and OSWorld-Verified, plus the VentureBeat summary of SWE-bench Pro (63.2% vs Sonnet 4.6’s 58.1% and Opus 4.8’s 69.2%), Terminal-Bench 2.1 (80.4% vs 67.0% and 82.7%), Humanity’s Last Exam (43.2% no tools / 57.4% with tools vs Opus 4.8’s 57.9% with tools), OSWorld-Verified (81.2% vs 78.5% corrected), and GDPval-AA v2 (1,618 vs Opus 4.8’s 1,615). The first independent benchmarks — SWE-Bench, Aider polyglot, MultiPL-E, Terminal-Bench, Vibe-Eval, etc. — will be the load-bearing independent evidence. Watch the first published independent eval and the first community reproduction.
2. The August 31, 2026 price transition. Watch the Anthropic pricing page and the Anthropic API reference for the rate card update on or after August 31, 2026. A team that ships agent code on Sonnet 5 in July should plan for the price transition in late August. The launch post has not announced an extension.
3. Effort-level adoption patterns. Will the agent ecosystem adopt the new effort-level parameter? Will third-party agent frameworks expose it as a config? Will Claude Code, Codex, and Cursor integrations pass it through? The Anthropic API release notes document the effort parameter as generally available for Sonnet 5 (no beta header required); the parameter is the new optimization dial. Watch for first-party framework support and for community benchmarks on the right effort level per workload.
4. Fable 5 returns, Claude Science, and Claude Tag follow-ups. The 2026-07-01 news radar recommended saving Fable 5 returns (and the proposed industry-wide jailbreak severity framework) for the Day 2 cycle, and Claude Science for a future cycle. The Sonnet 5 article can mention the same-day coordinated launch without duplicating those stories. Watch the AI Newsroom cycle for those follow-ups — see the AI Newsroom sitemap.
5. The Edit June 30, 2026 BrowseComp chart correction as a precedent for methodology transparency. Anthropic version-pinned the chart correction on launch day. Future model launches may follow the same pattern. The article preserves the precedent by citing the Changelog entry in both the body and the Sources block; watch for similar corrections on future Anthropic launches.
Sources
-
- Anthropic — “Introducing Claude Sonnet 5” (launch post, dated 2026-06-30; Changelog section with “Edit June 30, 2026” on the BrowseComp chart; “Edit June 30, 2026”-style methodology correction; the “most agentic Sonnet model yet” framing; the cost-performance chart on BrowseComp and OSWorld-Verified at four effort levels; the safety section with the Sonnet 5 < Sonnet 4.6 < Opus 4.8 misaligned-behavior ranking; the cyber capability section with the 0.0% / slightly-higher-partial-success Firefox 147 result; the 10 named partner quotes; the Availability and pricing section with $2/$10 intro through 2026-08-31 → $3/$15 standard; the three footnotes (Cyber Verification Program, 1.0–1.35x tokenizer change, April 26, 2026 rate-limit increase); the related-content block listing Fable 5 returns, Claude Science, and Claude Tag) (primary, 2026-06-30, live-verified)
-
- Anthropic — Claude Sonnet 5 System Card (the document referenced by the launch post as “Section 3.2.4” (cyber capability) and “Section 6.4” (automated behavioral audit); the standard methodology “10M token budget with compaction and programmatic tool calling” that the Edit June 30, 2026 chart correction aligned the BrowseComp chart to; 11,676,068 bytes returned 2026-07-01) (primary, 2026-06-30, live-verified)
-
- Anthropic — Pricing page (the
Sonnet 5model listing on the pricing page; the $2/$10 intro and $3/$15 standard rate card consistent with the launch post; 1,354,664 bytes returned 2026-07-01) (primary, 2026-06-30, live-verified)
- Anthropic — Pricing page (the
-
- Anthropic — Claude API reference, model listing (
claude-sonnet-5documented; effort-level parameter documented aseffort/effort level) (primary, 2026-06-30, live-verified)
- Anthropic — Claude API reference, model listing (
-
- Anthropic — Claude API release notes (the
effortparameter for Sonnet 5 documented as generally available — no beta header required — for Sonnet 5;effort leveldocumented aslow | medium | high | xhigh; default and override behavior described; the four-tier pricing and rate-limit work referenced) (primary, 2026-06-30, live-verified)
- Anthropic — Claude API release notes (the
-
- Mozilla — Security advisories index (the underlying Firefox 147 vulnerability advisories the Anthropic cyber evaluation was developed against, “in collaboration with Mozilla”; “all vulnerabilities have been patched in Firefox 148” per the Anthropic blog) (primary, 2026-06-30, live-verified)
-
- VentureBeat — “Anthropic launches Claude Sonnet 5 at a steep discount to its top model as the company races toward a blockbuster IPO” (Michael Nuñez, 2026-06-30, 11:00 am PT; secondary press confirmation of the launch, the $2/$10 → $3/$15 transition with the August 31, 2026 date, the Opus 4.8 $5/$25 rate card, the 1.0–1.35x tokenizer change, the SWE-bench Pro / Terminal-Bench 2.1 / Humanity’s Last Exam / OSWorld-Verified / GDPval-AA v2 benchmark numbers, the 0.0% / 13.2% partial-success Firefox 147 result for Sonnet 5 vs 8.8% for Sonnet 4.6, the Cyber Verification Program, and the “less strict than Fable 5” cyber-safeguards framing) (secondary, 2026-06-30, live-verified)
-
- AI Newsroom 2026-07-01 news radar sweep (Claude Sonnet 5 flagged as the day’s top candidate from the 2026-06-30 news cycle; the same-day Fable 5 returns and Google TabFM candidates held for the Day 2 and Day 3 cycles) (secondary, 2026-07-01, sitemap)
-
- AI Newsroom EditorInChief disposition 2026-07-01 (the commissioning decision: accept Claude Sonnet 5 as the day’s only article; reject the Headroom candidate brief as a duplicate of the 2026-06-24 Headroom article at news.lesbass.com/articles/headroom-ai-agent-token-compression/; the 5 load-bearing primary sources live-verified in the EditorInChief heartbeat) (secondary, 2026-07-01, sitemap)
-
- AI Newsroom article candidate brief: Claude Sonnet 5 (the accepted candidate; the 5-row candidate brief with the load-bearing primary sources; the brief that the Writer task is executing) (secondary, 2026-07-01, sitemap)